
Un ami me demandait récemment comment l’Entreprise Autonome fait pour assurer qu’une tâche programmée sera bien effectuée à l’instant prévu ? Un exemple typique est la gestion automatisée des contrats où il est nécessaire d’envoyer un courrier de résiliation 3 mois avant la date d’expiration, sachant que cette dernière est dans 5 ans.
Les promesses n’engagent que ceux qui les écoutent !
Bien sûr, il est possible de souscrire à un service SaaS qui gère ce type de situation. Hyperlex conviendrait dans l’exemple mentionné ci-dessus. Mais il y a toujours le risque du dysfonctionnement du service à la date programmée ou simplement la disparition de l’entreprise SaaS dans l’entre-temps. La promesse de la bonne exécution est donc à prendre avec beaucoup de réserve, d’autant plus que l’échéance est lointaine.
Les solutions et leurs risques
Suivant les conséquences de la non exécution de l’action à l’instant prévu (par exemple l’envoi du courrier de résiliation n’a pas lieu), on peut choisir parmi différents niveaux de sûreté de fonctionnement.
Niveau 1 : Usage d’un grand opérateur
Fonctionnement
On peut penser que Microsoft ou Google seront toujours présents dans quelques années et que leur service de Calendrier sera toujours actif. Il est alors possible de créer un événement dans un calendrier et de déclencher une action sur la notification de l’occurrence (courrier électronique par exemple). Google permet de programmer des événements sur un horizon de 100 ans (bel optimisme !) à partir de la date courante (à en croire ce que l’interface permet de faire). L’API est cependant non limitative sur la date suivant la documentation. Cette solution est simple et redondée par Google à coût quasi nul. Vous pouvez utiliser un service tel que Moskitos, Zapier ou MuleSoft pour convertir l’événement Google Calendar en des actions beaucoup plus évoluées qu’une simple notification. Dans l’exemple ci-dessous nous déclenchons une action dans salesforce.
Analyse de risques
La figure suivante présente les composants mis en jeu dans notre exemple :
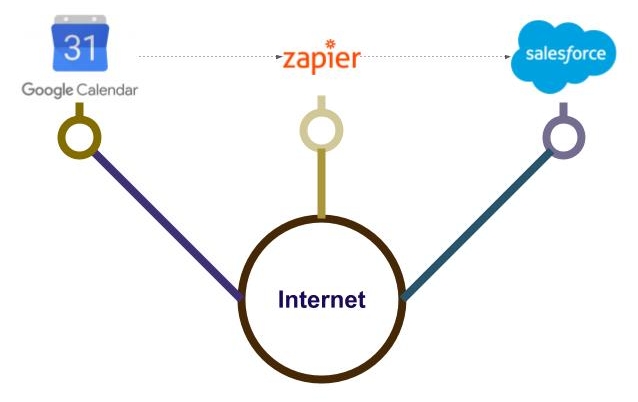
Le risque de non réalisation de l’événement dans salesforce est dû aux causes suivantes :
- Disparition du service de Google
- Panne momentanée du service Calendar de Google
- Évolution des interfaces Google ou/et Zapier rendant la demande de service implémentée obsolète
- Panne réseau entre Google et Zapier
- Disparition du service Zapier
- Panne momentanée de Zapier
- Évolution des interfaces Zapier ou/et salesforce rendant la demande de service implémentée obsolète
- Panne de réseau entre Zapier et salesforce
- Panne de momentanée de salesforce.
En fait, l’Entreprise Autonome rencontre toujours les 4 mêmes sortes de risques dans son système d’information :
- la disparition commerciale du service souscrit
- la panne du service souscrit
- l’évolution des API entre services rendant l’implémentation obsolète
- la panne réseau entre services souscrits (Internet ou lignes dédiées).
Niveau 2 : Surveillance
Les patterns solution
Réaliser le Niveau 1 mène vraisemblablement à l’échec. En effet laisser tourner un système d’information en espérant qu’il fonctionnera toujours dans 5 ans serait simplement naïf. Que l’événement programmé dans Google Calendar soit toujours bien présent, nous l’espérons, mais nous n’en avons aucune certitude. De même, les API de Google, Zapier et salesforce auront évolué. Tout cela na marchera donc plus comme ce fut le cas au premier jour.
Les patterns de solutions automatisées sont :
- surveiller les services
- surveiller le fonctionnement des échanges inter-services de manière active
- surveiller les évolutions d’API
- redonder les services
- redonder les réseaux.
Surveiller les services
Nous utilisons des services comme Witbe pour surveiller les services. Pour cela nous réalisons des points d’accès de test spécialement dédiés et en double : un point d’accès est censé être toujours fonctionnel et un autre est volontairement mis en panne périodiquement pour vérifier que le service de monitoring fonctionne. En cas de panne d’un des deux, une alarme et l’action de diagnostic est déclenchée.
Surveiller les échanges inter-services
Dans le cas du service Calendrier à long terme, nous réalisons une chaîne de traitement de test qui parcourt l’ensemble des étapes que l’événement (qui devra être traité « à coup sûr ») emprunterait si nous étions à l’instant fatidique ! Un calendrier de test est donc actif et un agent de vérification surveille dans salesforce que l’événement y est bien parvenu. En cas de manque, un diagnostic est lancé. De même, le calendrier de test pourra disposer de « pièges » périodiques pour tester si l’agent de surveillance fonctionne correctement.
De même cet agent observe si l’effet escompté d’un événement calendrier « réel » et non de test, est bien répercuté applicativement. Dans notre exemple, cet agent vérifie la présence dans salesforce du message attendu.
Surveiller les évolutions des API
Dans le cas de Google Calendar on retrouve la version dans l’url : https://www.googleapis.com/calendar/v3 . Pour Zapier nous faisons de même, la version de l’API étant indiquée dans la clef « version » du descriptif de l’App /AppSchema.
Un agent de test vérifie que les opérations effectuées sur l’API renvoient toujours les codes de résultat correctement. Si l’API n’a pas le comportement attendu une alerte est renvoyée.
Notre système avec surveillance
La figure suivante présente les outils de surveillance qui permettent de détecter des dysfonctionnements de manière anticipée. Les systèmes de surveillance sont eux même testés en créant des anomalies volontaires et en surveillant leur bonne détection.
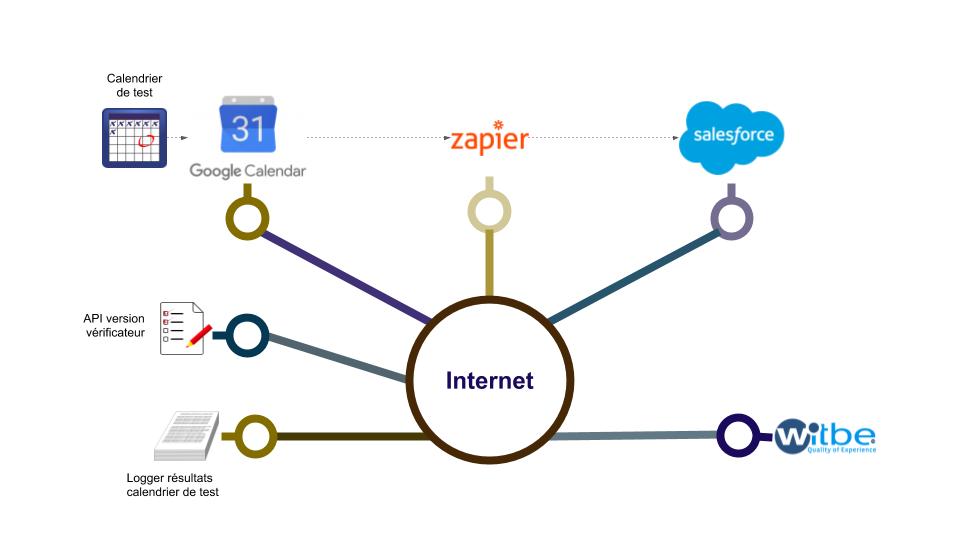
Niveau 3 : Redondance
Redondance des calendriers
Il est possible que Google soit absent au moment fatidique d’envoyer le message à salesforce. Il est évident que la Loi de Murphy s’appliquera d’autant plus que l’enjeu est important ! Nous pouvons donc disposer de deux calendriers qui ont le même planning et les faire fonctionner en parallèle. Par exemple Office365 et Google Calendar. Ils sont synchronisables par un service redondé comme Moskitos ou Zapier. Nous avons évidemment le problème du doublon de messages qui vont arriver dans salesforce. Pour le résoudre ce problème, les événements placés dans les calendriers auront un même identifiant unique.
Redondance des systèmes d’échange
Un système tel que Crosscut de Moskitos est à lui seul un système distribué et redondé. Mais il est possible d’utiliser deux queues de synchronisation XXXX mettra en attente les messages redondants ayant un même identifiant le temps de vérifier que l’effet attendu dans salesforce soit bien effectué après la libération du premier message. Ce pattern de redondance et synchronisation est par exemple utilisé dans les queues redondantes de RabbitMQ. Une fois cela assuré, la queue de synchronisation supprimera les messages redondants.
Redondance du réseau
Le système étant 100 % dans le cloud, l’utilisateur a apparemment peu la main sur la qualité du réseau entre deux fournisseurs SaaS/PaaS. Il est alors possible d’utiliser un pattern de plateforme intermédiaire comme décrit dans les architectures de référence de l’ioakb. Dans ce cas, les communications entre cloud opérateurs passent par une plateforme qui permet de définir la route entre deux opérateurs. Toutefois tout cela devient assez voire trop compliqué :
- Si nous voulons éviter d’alourdir l’infrastructure, nous pouvons déjà constater que les grand opérateurs comme AWS et Google disposent de leur propre réseau hautement disponible et qu’ils l’utilisent pour router au niveau mondial dans leur propre AS. En outre, des liens hautement disponibles existent entre Google et AWS. Il semble difficile de faire mieux.
- Nous pensons profitable d’étudier les réseaux des grands opérateurs et de les utiliser à travers leurs peerings quand ils existent. L’adage de Saint-Exupéry est probablement la meilleure option : « La perfection est atteinte, non pas lorsqu’il n’y a plus rien à ajouter, mais lorsqu’il n’y a plus rien à retirer. »
Redondance des agents de surveillance
Leur redondance est aisée à réaliser car au pire les agents redondés doubleront l’occurrence des alarmes.
Le traitement des alarmes
In fine les détections de dysfonctionnement et les alarmes engendrées déclenchent des processus de traitement des problèmes. Pour une entreprise de main d’œuvre, un humain pourra exécuter les actions correctives et/ou palliatives prévues. Pour une Entreprise Autonome, un processus automatisé prendra le relais. Dans ce cas, le bon déroulement du processus devra être lui même surveillé.
Conclusion
Se baser sur les offres « Calendrier » des grands opérateur cloud est une bonne base pour réaliser un service de planification et d’orchestration à long terme. Toutefois, tous les patterns de sécurisation du SI 100% cloud doivent être pensés et appliqués si l’on souhaite réellement profiter d’une haute fiabilité.
Activités d’AVERATIO
AVERATIO fournit des services de conception et de réalisation de l’intégration à haute fiabilité de systèmes SaaS. N’hésitez pas à nous contacter pour toute demande : info@averatio.com
Crédits
- Merci à hypocore pour le clipart de calendrier
- Merci à palimpsest pour le clipart de pile de papier
- Merci à DaKo pour le clipart de liste